Attention Mechanism in Deep Learning: Bahdanau vs Luong
29 December 2021
Introduction and Context
Today we’re going to cover an interesting topic of Deep Learning, we going to discover what’s attention mechanism, why do we need them and in particular we going to cover three types of attention mechanism: Luong Dot Attention, Luong General Attention and Bahdanau Attention.
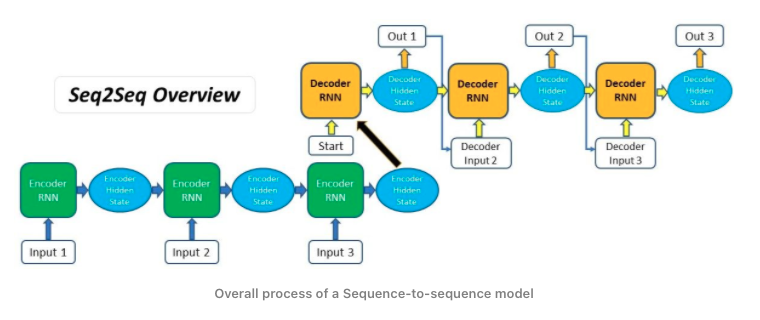
Attention mechanisms form part of modern language models. Let’s consider that we have a sequence-to-sequence recurrent model that takes a sequence of items that could be words, letters, image frames, etc; and outputs another sequence of items. The model could be defined based on an encoder-decoder architecture where the encoder compiles the information, captures into a vector (called the context). Once the input information is processed the encoder sends the context to the decoder, which begins producing the output sequence item by item.
The problem that sequence-to-sequence models usually have is that they are not able to accurately process long input sequences, since only the last hidden state of the encoder RNN is used as the context vector for the decoder.
In order to tackle this issue attention mechanisms were introduced.
Attention Mechanisms
The idea behind the attention mechanism is to allow the decoder part to utilize the most relevant parts of the input sequence in a flexible way, through a weighted combination of all of the encoded input vectors, having the most relevant vectors being attributed the highest weights. It is accomplished by creating a unique mapping between each time step of the decoder output to all the encoder hidden states. This means that for each output that the decoder makes, it has access to the entire input sequence and can selectively pick out specific elements from that sequence to produce the output.
The general attention mechanism has three main components: the queries Q, the keys K, and the values V. The general attention mechanism performs the following computations:
- Computation of the alignment score value: $Score = Q * K$
- Generation of the attention weights: $a = softmax(score)$
- Generation of the context vector: $c = \sum a * V$
Within the ddescribed principles of Attention there are 2 main types, their differences consist mainly in their architectures and computations of the alignment score value.
Bahdanau Attention
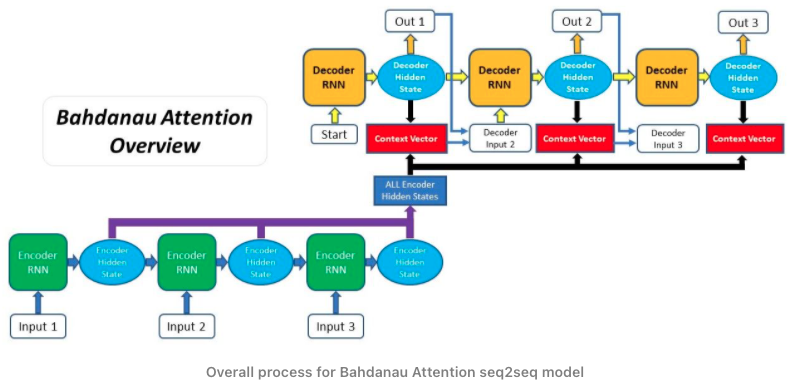
This method aims to improve the sequence-to-sequence model by aligning the decoder with the relevant input sentences and implementing Attention. The entire step-by-step process of applying Bahdanau Attention is the following:
- Encoder produces hidden states of each element in the input sequence
- Calculating Alignment Scores between the previous decoder hidden state and each of the encoder’s hidden states are calculated
- Alignment scores for each encoder hidden state are combined and represented in a single vector and subsequently softmaxed
- The encoder hidden states and their respective alignment scores are multiplied to form the context vector
- The context vector is concatenated with the previous decoder output and fed into the Decoder RNN for that time step along with the previous decoder hidden state to produce a new output
- The process (steps 2-5) repeats itself for each time step of the decoder until an token is produced or output is past the specified maximum length
Its alignment score formula looks as the following:
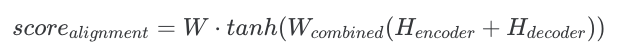
Its implementaion with python and tensorflow looks as the following:
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W1 = tf.keras.layers.Dense(units)
self.W2 = tf.keras.layers.Dense(units)
self.V = tf.keras.layers.Dense(1)
def call(self, query, values):
query_with_time_axis = tf.expand_dims(query, 1)
# Bahdanau score
score = self.V(tf.nn.tanh(self.W1(query_with_time_axis) + self.W2(values)))
# attention_weights shape == (batch_size, max_length, 1)
attention_weights = tf.nn.softmax(score, axis=1)
# context_vector shape after sum == (batch_size, hidden_size)
context_vector = attention_weights * values
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights
Luong Attention
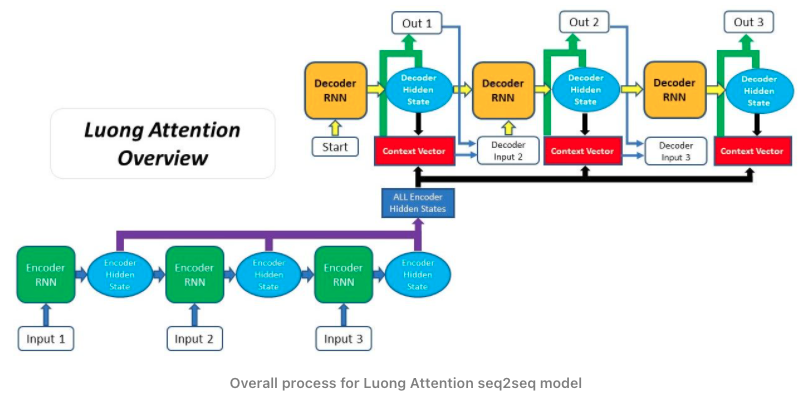
Comparing to the Bahdanau Attention, Luong Attention has different general structure of the Attention Decoder as the context vector is only utilised after the RNN produced the output for that time step. The entire step-by-step process of applying Luong Attention is the following:
- Encoder produces hidden states of each element in the input sequence
- Decoder RNN - the previous decoder hidden state and decoder output is passed through the Decoder RNN to generate a new hidden state for that time step
- Using the new decoder hidden state and the encoder hidden states, alignment scores are calculated
- The alignment scores for each encoder hidden state are combined and represented in a single vector and subsequently softmaxed
- The encoder hidden states and their respective alignment scores are multiplied to form the context vector
- Producing the Final Output - the context vector is concatenated with the decoder hidden state generated in step 2 as passed through a fully connected layer to produce a new output
- The process (steps 2-6) repeats itself for each time step of the decoder until an token is produced or output is past the specified maximum length
Its alignment score formula and implementation can be split on dot and general versions.
Luong Attention Dot version
The alignment score formula for dot version looks as the following:
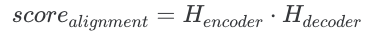
Its implementaion with python and tensorflow looks as the following:
class LuongDotAttention(tf.keras.layers.Layer):
def __init__(self):
super(LuongDotAttention, self).__init__()
def call(self, query, values):
query_with_time_axis = tf.expand_dims(query, 1)
values_transposed = tf.transpose(values, perm=[0, 2, 1])
# LUONG Dot-product
score = tf.transpose(tf.matmul(query_with_time_axis,
values_transposed), perm=[0, 2, 1])
# attention_weights shape == (batch_size, max_length, 1)
attention_weights = tf.nn.softmax(score, axis=1)
# context_vector shape after sum == (batch_size, hidden_size)
context_vector = attention_weights * values
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights
Luong Attention General version
The alignment score formula for general version looks as the following:
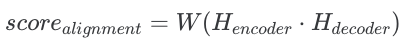
Its implementaion with python and tensorflow looks as the following:
class LuongGeneralAttention(tf.keras.layers.Layer):
def __init__(self, size):
super(LuongGeneralAttention, self).__init__()
self.W = tf.keras.layers.Dense(size)
def call(self, query, values):
query_with_time_axis = tf.expand_dims(query, 1)
values_transposed = tf.transpose(self.W(values), perm=[0, 2, 1])
# LUONG General
score = tf.transpose(tf.matmul(query_with_time_axis, values_transposed), perm=[0, 2, 1])
# attention_weights shape == (batch_size, max_length, 1)
attention_weights = tf.nn.softmax(score, axis=1)
# context_vector shape after sum == (batch_size, hidden_size)
c = attention_weights * values
context_vector = tf.reduce_sum(c, axis=1)
return context_vector, attention_weights